지금까지 여러 Latent Diffusion 모델을 드림부스로 특정 대상에 대한 개념을 파인튜닝 해보면서 어떤 설정이나 데이터셋에 따라서 결과에 차이가 발생한다는 것을 알게되었지만, 어느정도의 유의미한 차이가 있는지 판단에 어려움이 있었다. 그래서 나는 생성모델을 수학적으로 평가하는 방법들에 대하여 알아보았다.
평가요소
우선, Latent Diffusion 모델과 같은 이미지 생성모델을 평가하려면 어떤 요소들을 고려해야 할지 알아보자
- Fidelity (충실도) : 이미지의 질 (실제와 얼마나 유사한가?)
- Diversity(다양성) : 이미지의 다양성
이렇게 크게 두가지가 있다.
생성 모델에서 출력한 이미지의 질은 당연히 중요하고, 생성 모델이 다양한 결과물을 출력할 수 있어야 생성모델이 진정한 생성모델이라고 할 수 있다.
그런데 이미지의 Fidelity 와 Diversity를 어떻게 측정할 수 있을까?
단순히 생각해보면, Fidelity는 학습한 원본 이미지와 얼마나 유사한지, Diversity는 출력한 이미지의 분산을 계산하면 알 수 있을 것이다.
하지만, 이미지의 차이를 측정하는 것은 그렇게 단순한 것이 아니다.
이미지는 비교하는 방법에는 픽셀 거리(Pixel Distance), 특징 거리(Feature Distance)를 측정하는 두 방식이 있으며 픽셀거리는 단순히 픽셀의 값 차이로 이미지의 변화를 측정하는 것이고, 특징 거리는 딥러닝의 여러 방법(PCA, 분류 모델 등)을 이용하여 특징벡터를 추출하여 차이를 계산하는 것이다.
생각을 해보면, 픽셀거리는 거의 동일한 이미지를 비교하는 데에는 유의미하겠지만 다양한 이미지를 출력하는 생성모델의 성능을 평가하는 데에는 부적합할 것이다. 따라서 생성모델을 평가할 때 사용하는 특징 거리를 측정하는 여러 방법들을 알아볼 것이다.
IS(Inception Score)
Inception Score는 원본 이미지(Ground Truth)없이 생성한 이미지의 분포만으로 모델의 성능을 평가한다.
Inseption Score는 Sharpness와 Diversity의 KLDivergence으로 정의되는데, 일단 정보의 엔트로피라는 개념을 알아야 의미를 이해할 수 있다. 엔트로피는 확률분포가 가지는 정보의 확신도 혹은 정보량을 수치로 표현한 것이다. 확률분포에서 특정한 값이 나올 확률이 높아지고 나머지 값의 확률은 낮아진다면 엔트로피가 작아진다. 반대로 여러가지 값이 나올 확률이 대부분 비슷한 경우에는 엔트로피가 높아진다. 연속확률 변수에서 엔트로피의 정의 : $H[Y] = \int_{\infty}^{\infty} p(y)log_2p(y)dy$
Sharpness는 $S = exp(E_{x~p}[\int c(y|x) \log c(y|x) dy])$로 정의할 수 있는데, classifier의 predictive distribution ${c(y|x)}$의 엔트로피가 낮아질수록, 즉 classifier가 더 확실하게 분류할 수 있는 이미지 일수록 값이 커진다.
Diversity는 $D = exp(-E_{x~p}[\int c(y|x) \log c(y) dy])$ 로 정의되며, 여기서, ${c(y|x)}$는 classifier의 marginal distribution 으로 이 값이 큰 엔트로피를 가질수록 diversity가 크다고 할 수 있다. 여기서 distribution을 측정할때, classifier 모델은 Inceptionv3 라는 모델을 사용하는것이 보통인듯하다.
IS의 단점은 분류기 모델의 훈련 데이터 세이트에 없는 무언가를 생성하는 경우 분류가 어렵기 때문에 낮은 점수를 받을 수 밖에 없다. 또한 분류기가 분류하는 같은 class 내에서 다양성을 측정 할 수 없다. 예를 들어, 남성과 여성을 분류하는 모델이 있을때 모든 남성이 같은 남성인지 다른 남성 여러명인지 점수를 통해 구분할 수 없다.
FID(Frechet Inception Distance)
FID는 생성 이미지와 원본 이미지의 집합을 서로 비교하여 구하는데, 다음 식과 같이 계산된다.
$FID = |\mu_{ T }- \mu_{G}|^2 + Tr(\Sigma_{T } + \Sigma_{G} - 2(\Sigma_{T } \Sigma_{G})^{1/2})$
$Tr$은 행렬의 대각 성분의 합을 의미한다.
$|\mu_{ T }- \mu_{G}|^2$는 생성 이미지(G 집합)와 원본 이미지(T 집합)의 평균의 차를 빼고 제곱한다. 이 값은 실제 이미지와 생성된 이미지의 차이를 의미하며, 이 값이 작을수록 유사한 이미지이므로 Fidelity도 높다고 판단하는 것이다.
$Tr(\Sigma_{T } + \Sigma_{G} - 2(\Sigma_{T } \Sigma_{G})^{1/2})$ 는 Diversity를 구하는 부분으로 T와 G 집합의 공분산을 구하는 방법이다. Diversity도 원본인 T 집합과 비슷할수록 높은 점수가 부여된다.
결론적으로, FID는 원본 이미지셋과 분포가 유사할 수록 점수가 높다고 할 수 있다.
Improved Precision and Recall
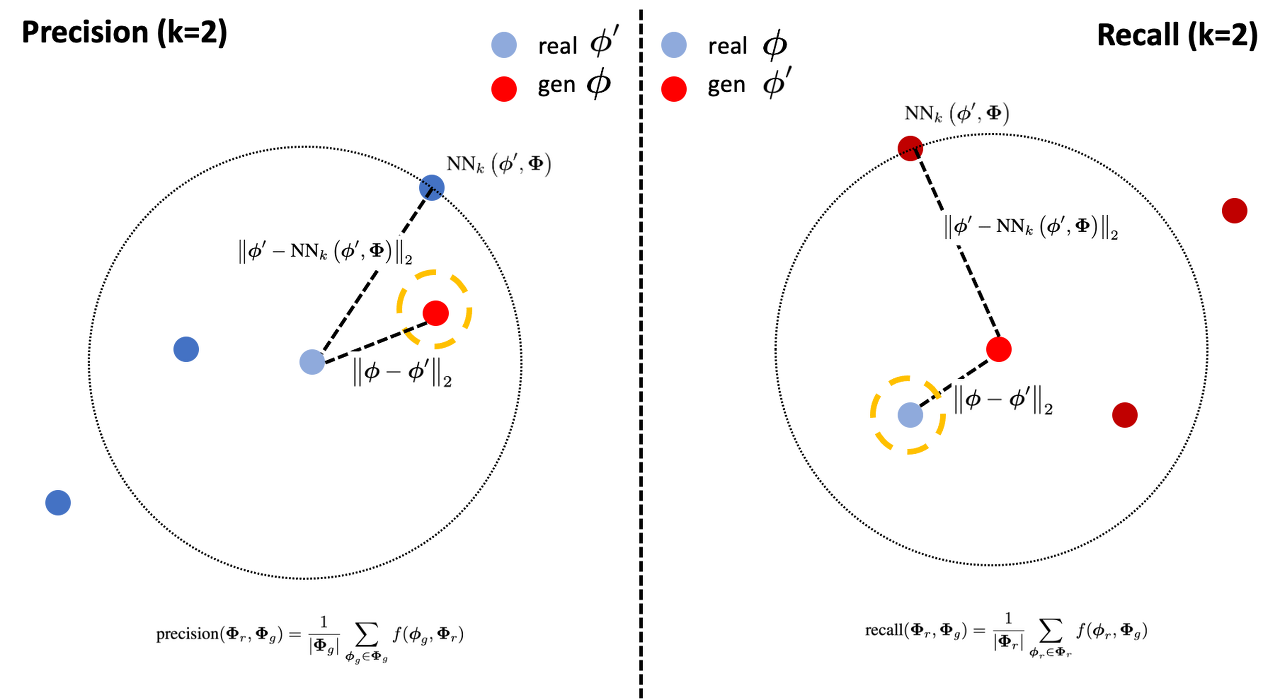
Precision and Recall 을 직역하면 정밀도와 재현율 이라는 뜻이다.
아래 그림을 통해 알기 쉽게 설명해보겠다.

위 그림의 $P_{r}$은 실제 집합, $P_{g}$는 가짜로 생성된 집합이다.
Precision은 fidelity를 의미하는데, 이는 $P_{r}$에 포함된 $P_{g}$ 원소의 개수와 같다. 이 뜻은 생성한 가짜 이미지가 실제 집합에 포함된 개수를 의미한다.
Recall은 diversity를 의미하고, 이는 $P_{g}$에 포함된 $P_{r}$의 개수와 같다. 그 말은 가짜 집합에 포함된 실제 이미지의 개수를 의미하고, 가짜 집합의 범위가 넓을 수록 더 높은 값을 가지게 된다.
그런데 여기서 $P_{r}$과 $P_{g}$를 어떻게 구해서 이걸 계산할 수 있을까?
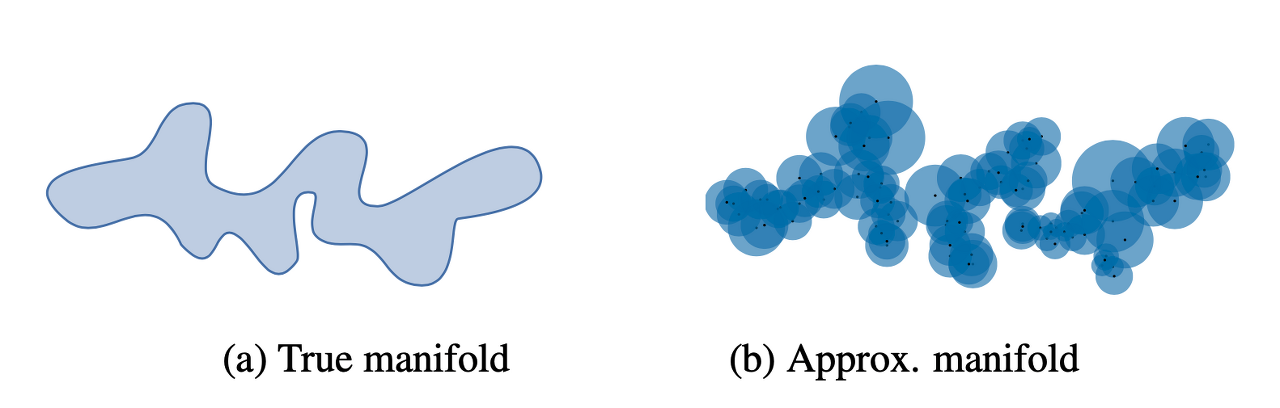
바로, k-Nearest Neighborhood 알고리즘을 사용해서 각 $P_{r}$ 과 $P_{g}$ 의 manifold를 근사하는 것이다.
그리고 아래 함수를 통해서 해당 sample이 집합에 속하는지를 판단할 수 있다.
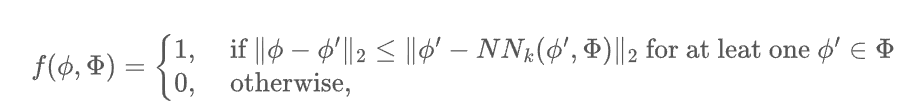
위 함수를 이용하여 수식으로 precision and recall을 정의하면 아래와 같다.
$\text{precision}(\Phi_r, \Phi_g) = {1 \over |\Phi|} \sum_{\phi_g \in \Phi_g} f(\phi_g , \Phi_r) \\ \text{recall}(\Phi_r, \Phi_g) = {1 \over |\Phi_r|}\sum_{\phi_r \in \Phi_r} f(\phi_r, \Phi_g)$
Density and Coverage
네이버 Clova AI 팀에서 발표한 측정 방식 (논문)이다.
앞에서 설명한 측정 방식인 Precision and Recall을 개선하기 위해 Density and Coverage 라는 측정 방식을 추가했다.
일단 논문에서 Precision과 Recall을 표현한 방식으로 다시 표현하면 아래와 같다.

($\text{NND}_{k}(X_{i})$는 k번째로 가까운 이웃의 거리(kth-nearest neighbour), $B(x,r)$은 점 x에 r 반경 이내에 존재하는 지점)
manifold를 다음과 같이 정의하면, 위에서 보여준 이 그림과 같다.
manifold를 이용하여 precision and recall을 표현하면 아래와 같다.

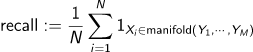
(X집합은 실제 데이터, Y집합은 가짜 데이터)
연구진은 precision and recall이 outlier(이상치)에 너무 민감하고, fake manifold가 너무 넓게 측정되어 recall 수치가 높게 나오는 문제를 해결하기 위해 Density and Coverage를 제안했다.
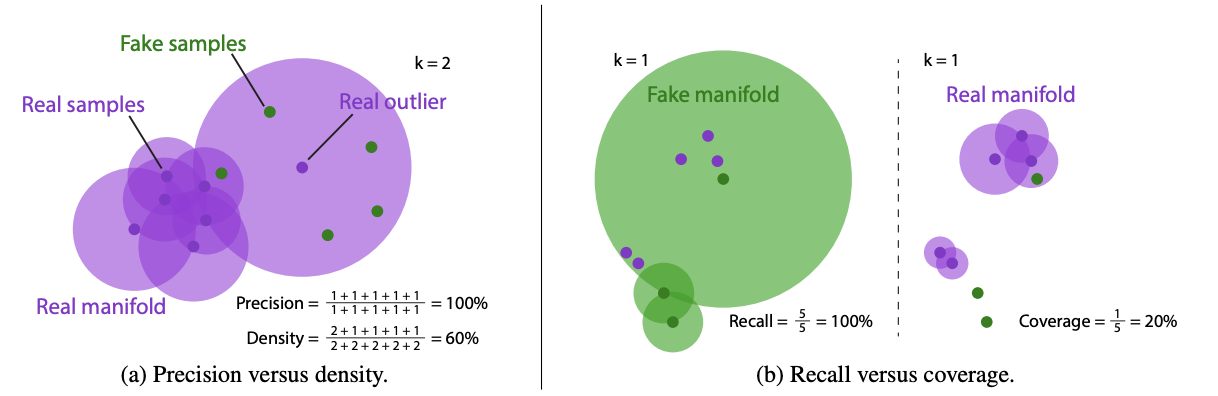
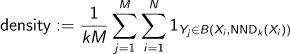
Precision을 대체하기 위한 Density는 말 그대로 sample의 밀도를 이용하여 측정하는 점수이다. 이런 방식을 적용한 이유는 outlier에 덜 민감하도록 만들기 위해서이다. 그렇다면 데이터셋에 outlier가 없는것이 검증되었을 경우 쓸 필요는 없어 보인다.
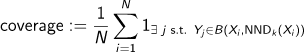
Coverage는 Diversity를 측정하기 위한 것으로, 전체 real manifold 중에 생성된 샘플이 하나라도 포함된 manifold의 개수를 의미한다. recall 과는 달리 이상치가 나올 확률이 적은 real 매니폴드를 이용하여 측정하기 때문에 fake 매니폴드의 이상치에 덜 민감하다고 할 수 있다.
Density and Coverage는 FID, IS등의 single-value metric의 fidelity와 diversity를 구별하여 평가할 수 없던 단점을 극복하고 outlier에도 덜 민감한 metric이라는 장점이 있다. 단점은 Density의 값이 100을 넘을 수가 있어 절대적인 측정값으로 표현할 수 없다는 점 정도인듯 하다.
내가 찾아본 모델 평가 방법은 IS를 제외하고 모두 원본 데이터셋과 분포를 비교하여 평가하는 방식이었다, 그런데 드림부스의 경우, 일반적인 파인튜닝과 달리 적은 데이터셋을 사용한다. 따라서 원본 데이터셋의 diversity가 떨어질수 밖에 없어 오히려 더 diversity가 적은 모델이 더 높은 점수가 나올 가능성이 높아보인다. 애초에 드림부스는 diversity가 목적이 아니라 fidelity가 주된 목적이므로 diversity는 중요도가 낮을지도 모르겠다.
아니면 측정할때 pretrained 모델을 학습할때 사용한 큰 데이터셋을 이용해야 하나? 잘 모르겠다.
아무튼 내가 결론을 내린 바로는 단일 점수로 값이 출력되는 FID, IS는 부적합해보이고, PRDC가 Precision, Recall, Density, Coverage를 전부 각각 측정하기 때문에 가장 좋을 것 같다.
다른 생각이나 좋은 방법을 아는 사람이 있다면 댓글을 달아주었으면 좋겠다.
참고문헌
'AI' 카테고리의 다른 글
| [딥러닝 연구] Classifier-Free-Guidance(CFG)와 Stable diffusion 파인튜닝 (0) | 2023.02.18 |
|---|---|
| [딥러닝]Text to Image 모델 드림부스 학습의 Diversity를 높이는 방법 (4) | 2023.02.01 |
| [논문 리뷰] Dreambooth의 원리와 기본적 이해 (0) | 2022.12.22 |
| Stable Diffusion이 대체 무엇일까?(Latent Diffusion의 작동 원리) (3) | 2022.11.28 |
| VScode 한글 소스 코드 Unable to debugging 오류 해결 방법 (+ CodeRunner 없이 단일 파일 테스트로 실행하기) (0) | 2022.07.18 |