동기
10만장 정도의 중규모? 멀티 레이블 캡션-이미지 데이터셋을 구축해서 새로운 모델을 파인튜닝하려고 시도 중인데, 기존에 시도했던 수많은 파인튜닝 모델들이 공통적으로 데이터셋이 적은 class는 학습이 되지 않거나, 대충 오버샘플링 할 경우 과적합 된 것 처럼 diversity가 매우 낮다는 문제가 있어 이러한 클래스 불균형 문제를 해결하기 위한 여러 방법을 정리하고 이를 바탕으로 새로운 아이디어를 제시해보고자 한다.
클래스 밸런싱이란?
클래스 밸런싱은 원래 분류 모델에서 자주 거론되는 클래스 불균형을 해결하는 방법을 일컫는 말이다. 클래스 불균형은 말 그대도 데이터셋에 존재하는 각 클래스의 데이터의 양이 고르지 않은 것을 의미한다. 클래스 불균형은 딥러닝 및 머신러닝에서 예측 성능 저하, 정확도 왜곡, 중요도 왜곡, 과적합의 원인이 될 수 있는 중요한 문제이다. 예를 들자면, 분류 모델에서 대부분의 99%의 데이터셋이 사과이고 1%가 배라면 모델은 분류 결과를 사과에 치우치게 나타낼 것이다. 이 외에도 지도학습을 사용하는 생성 모델을 포함한 다양한 딥러닝/머신러닝 모델에서 문제를 일으킬 수 있다.
Stable Diffusion에서도 마찬가지로 비슷한 문제를 일으킨다. Dreambooth 방법을 사용하여 특정 캐릭터들을 학습할 때, 데이터셋이 클수록 데이터셋에 포함된 여러 캐릭터의 그림의 양이 매우 불균형한 경우가 많다. 이렇게 클래스가 불균형한 학습으로 인해 데이터 양이 많은 캐릭터는 잘 출력하지만 적은 캐릭터는 출력하지 못하는 경우가 있다. 이런 문제를 해결하는 최적의 방법을 찾기 위해 클래스 밸런싱을 하는 방법에는 어떤 것이 있는지 알아보자.
오버샘플링&언더샘플링

가장 단순한 방법으로, 오버샘플링은 단순히 데이터가 적은 클래스가 있다면 클래스에 포함된 데이터의 양을 똑같이 늘려주는 것이고 언더샘플링은 데이터가 많은 클래스에서 랜덤하게 데이터를 삭제해서 다른 클래스랑 똑같은 양을 가지게 만드는 것이다.
오버샘플링은 데이터의 양을 늘릴 때 사용할 수 있는 여러 가지 방법이 있는데 방법을 기준으로 분류하면 크게 단순 오버 샘플링과, 알고리즘 오버 샘플링으로 나눌 수있다. 단순 오버샘플링은 단순하게 같은 클래스의 데이터에서 랜덤하게 복사해야 양을 늘리는 것이고, 알고리즘 오버 샘플링은 기존 데이터를 바탕으로 ADASYN, SMOTE와 같은 특수한 알고리즘을 사용하여 데이터를 생성하여 양을 늘린다. 언더 샘플링도 삭제한다는 점만 다르고 나머지는 오버 샘플링과 마찬가지이다.
이런 방식에는 한계점이 존재하는데, 단순 오버샘플링은 같은 데이터를 그대로 복사하는 방식이기 때문에 데이터셋이 작은 경우 과적합이 발생할 가능성이 높고, 언더 샘플링은 데이터 양이 많은 클래스의 데이터를 삭제하는 방식이라 데이터셋의 크기가 작아지면서 성능의 손실을 가져올 수 밖에 없을 것이다.
나는 지금까지 단순 오버샘플링으로 밸런싱을 한 뒤에 Stable Diffusion 모델을 파인튜닝했는데, 실제로 이미지의 숫자가 적으면 해당 class에서 과적합 증상이 나타나는 것을 확인했다.
가중치 밸런싱 (Weight Balancing, Cost-sensitive learning)
가중치 밸런싱은 언더샘플링, 오버샘플링과는 다르게 데이터의 양을 조절하는 것이 아니고, 데이터를 학습할 떼 들어가는 loss 가중치를 조절하여 밸런싱을 하는 것이다. 오버샘플링의 경우에는 부족한 데이터를 늘렸지만, Weight Balancing은 학습할 때 loss를 크게 만들어 학습의 균형을 맞춘다고 보면된다. 이때 loss를 조절하는 기준은 Focal Loss 등 여러 방법이 있지만 일반적으로 class-balanced loss는 클래스 빈도에 반비례하게 샘플 가중치를 할당한다고 한다(그러나 최근 연구에서는 이 방법은 성능이 떨어지기 때문에 대신 성능이 좋은 클래스 빈도의 제곱근에 반비례하게 설정된 smoothed 가중치를 사용했다.).
또한, 기존 오버샘플링은 중복된 샘플이 많아져서 훈련 속도가 느려지고 데이터 분포를 왜곡할 수 있으며 과적합에 취약하다는 단점이 있지만 가중치 밸런싱은 이러한 문제가 없다. 하지만 데이터 수가 너무 극단적으로 작으면 가중치 밸런싱을 해도 효과가 없을 수도 있다는 단점이 있다.
Class-Balanced Loss Based on Effective Number of Samples를 사용한 싱글 레이블 밸런싱
이 방법은 기존의 단순히 클래스 빈도에 반비례하도록 설정한 Class-balanced loss가 데이터셋의 양이 많아질 수록 새로운 데이터가 쌓이면 중복(overlap) 되는 정보가 많다는 점을 고려하지 않은 점을 지적하는 논문에서 제안한 방법이다.
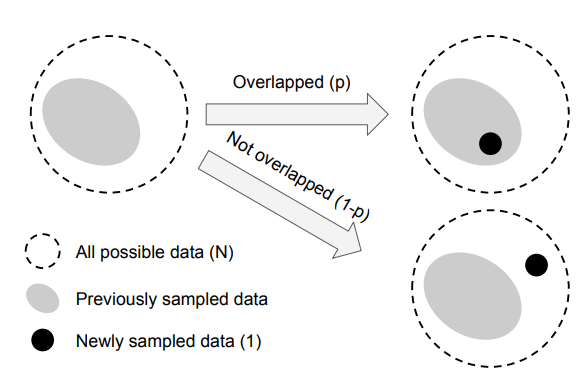
위 그림을 통하여 쉽게 이해해 보자. 우리가 어떤 대상을 이미지를 통해 학습 시킬때에는 대상을 표현하는 이미지가 필요하다. 학습하고자 하는 어떤 대상을 완전히 표현하는 모든 데이터의 집합을 위 그림에서 N 이라고 정의한다. 하지만 당연하게도 우리는 어떤 대상의 모든 데이터를 전부 샘플링할 수 없다. 그래서 우리는 샘플링할때 전체 집합 N에서 랜덤하게 추출한 데이터를 사용하여 학습시킨다. 그런데, 데이터가 많아질수록 우리가 새로 뽑은 샘플이 이미 이전에 샘플링한 데이터(Previously sampled data) 집합 안에 포함될 가능성은 당연히 높아질 것이다. 따라서 데이터셋의 수가 클수록 무조건 그에 비례하여 실질적인 정보량이 많아져 N에 가까워지는 것이 아니기 때문에 데이터셋에도 양이 늘어날 수록 얻는 편익이 줄어드는 한계 효용(marginal benefit)체감의 법칙이 존재한다는 것이다.
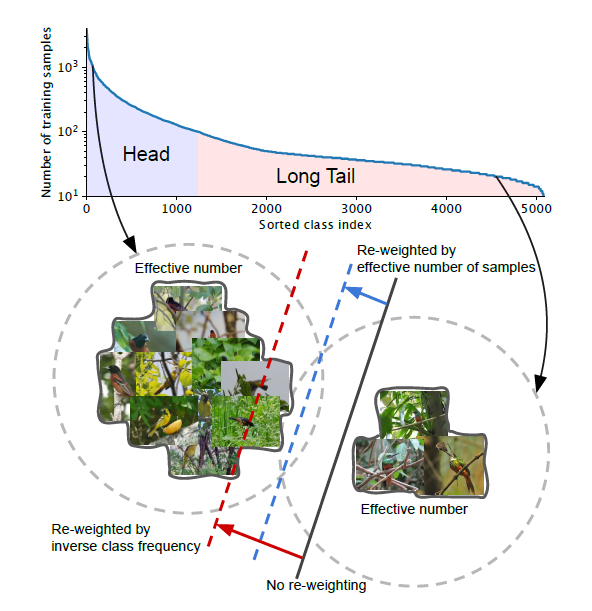
위에서 설명한 대로, 데이터셋의 수가 많을수록 데이터의 한계 효용은 줄어들기 때문에 기존 방법대로 class 에 속하는 데이터의 양이 클수록 비례하여 loss를 작게 만들면 과도하게 weighting 되므로 이런 한계 효용 (marginal benefit) 감소를 고려하여 loss를 조절해야 한다는 것이다. 그래서 논문에서는 샘플의 수에 따라서 실질적으로 얼마나 정보를 가지는지(논문에서는 샘플의 예상 볼륨 이라고 표현)를 나타내는 Effective Number 라는 것을 도입하여 한계 효용을 고려한 class-balanced loss를 만들었다.
논문에서는 샘플의 예상 볼륨을 의미하는 Effective Number를 구하기 위해서 샘플이 부분적으로 겹치는 경우는 제외하여 매우 간단한 수식 $E_n = \left ( 1-\beta^n \right )/\left ( 1-\beta \right ), where\;\beta = \left( N - 1 \right)/N$ ($n$은 샘플의 개수, $N$은 가능한 모든 데이터의 볼륨)으로 표현했다. 증명은 이전에 샘플링된 데이터와 겹칠 확률을 이용하여 계산하는데 생각보다 간단하다.


$E_n = \left ( 1-\beta^n \right )/\left ( 1-\beta \right ), where\;\beta = \left( N - 1 \right)/N$ 수식을 보면 알 수 있는 것은 지수 함수이기 때문에 $\beta$ 값에 따라서 굉장히 큰 차이가 생긴다는 점이다. 그런데 문제는 $\beta = \left( N - 1 \right)/N$인데 가능한 전체 모든 데이터의 볼륨의 크기 $N$를 어떻게 알 수 있냐는 것이다. 논문에서는 모든 클래스에 적합한 하이퍼파라미터 $N$의 최적값을 찾지 못했으며 이는 데이터셋과 클래스 종류에 따라 다를것이라고 말한다. 또한, Effective Number를 구할때 $\beta$를 임의의 값으로 설정하여 계산하는데 이 값을 적절하게 설정하는 것이 클래스 불균형을 효과적으로 감소시켜줄 것이라고 말한다. 논문에서도 이 $\beta$ 값을 어떻게 설정해야 하는지에 대한 답이 없다는 것을 보아 이것이 가장 큰 한계점이라고 볼 수 있다.
어쨌든 결과적으로, 논문에서는 Effective Loss를 적용한 class-balanced loss를 제시한다. 이 외에도 다양한 종류의 Softmax Cross Entropy Loss, Focal Loss 등에 적용한 수식이 있으므로 궁금하다면 논문을 참고하기 바란다.

이 방법은 데이터셋의 규모가 매우 커서 한계 효용이 감소하는 것이 눈에 띌 정도로 클래스의 데이터 양이 많을 때 유용한 방법일 것으로 보인다. 하지만 내 경우에는 각 클래스의 데이터가 300개 내외 이기 때문에 이런 방법이 유용할 것 같지 않다는 생각이 든다.
Distribution-Balanced Loss를 사용한 멀티 레이블 밸런싱
위에서 설명한 클래스 밸런싱 방법은 하나의 데이터가 단 하나의 클래스를 가지는 경우에만 적용 가능하고, 여러 클래스를 동시에 가지는 경우는 적용이 불가능하다. 여러 클래스를 동시에 가지는 객체의 분류 모델(한 사진에 여러 물체가 동시에 포함된 경우)이나 stable diffusion을 단순히 하나의 키워드로 파인튜닝시키는 것이 아니고 멀티 레이블 캡션으로 학습(예를 들어, 캐릭터와 옷, 배경을 동시에 캡션에 넣는 경우)하는 경우가 이에 속한다. 멀티 레이블 데이터의 경우 밸런싱은 단순히 오버 샘플링을 하는 것도 굉장히 어려운 최적화 문제이다. 이미지를 오버샘플링으로 늘리면 이미지가 여러 레이블을 가지며 레이블 간 상호 연관성도 존재하기 때문에 다른 레이블도 같이 늘어날 수 밖에 없기 때문이다. 이런 복잡한 수학 문제 풀이를 수만 장이 넘는 데이터에 할 수 있을까?
그래서 멀티 레이블 클래스 밸런싱을 하는 방법에 대한 논문(Distribution-Balanced Loss for Multi-Label Classification in Long-Tailed Datasets)을 찾아봤다. 이 논문은 long tailed 클래스 분포로 인한 멀티 레이블 인식 문제를 위해 Distribution-Balanced Loss 라는 새로운 가중치 밸런싱 방법을 제안했다. 해당 논문에서는 멀티 레이블 클래스 밸런싱의 문제를 해결하는 레이블의 공존성을 고려한 가중치 재조정과 주로 분류 모델에서 쓰이는 손실함수인 Binary Cross Entropy (BCE) loss에서 존재하는 부정 레이블의 과도한 억제(over-suppression)를 완화하기 위한 부정 허용 정규화(negative-tolerant regularization)를 제안한다.(재미있는 점은 Diffusion model도 BCE와 비슷한 Cross Entropy Loss를 사용한다는 점과, Stable Diffusion 모델은 inference 과정에서 unconditional(negative) likelihood를 아예 빼버리는 Classfier-free guidance를 사용하고 추가적인 negative prompt를 사용하기도 한다는 점인데 이런 유사성 때문에 논문에서 말한 문제점과 비슷한 현상이 Stable Diffusion에서도 발생할 것 같다는 생각이 든다.)
레이블의 공존성이란 위에서 설명했듯이 레이블 간에 연관성이 있어 같이 존재하는 경우가 흔한 것을 말하는데 예를 들어, 이미지에서 'tree'와 'river'는 같이 존재할 확률이 높을 것이다. 따라서 이런 이미지들을 다시 수집해도 이런 라벨 간의 연관성으로 인해 균형 잡힌 데이터가 나오지는 않을 것이다.
부정 레이블/클래스(negative label/class) 는 이미지에서 나오지 않은 클래스들을 의미한다. 각 이미지는 일반적으로 수많은 클래스 중에 몇개 정도의 매우 적은 클래스와 연관되어 있기 때문에 대부분의 클래스는 negative로 간주된다. Binary Cross Entropy Loss에서는 이런 negative class의 편향으로 over-suppression이 발생한다고 주장한다.
논문에서는 위에서 설명한 두 가지 문제를 해결하기 위한 두 가지 방법을 제시하고 이 두가지 방법을 합쳐 새로운 loss인 Distribution-balanced loss를 제안한다.

위에 정의된 내용을 통하여 $y^k_i$는 샘플 이미지 $x^k$가 $i$ 클래스에 속하면 1이고 속하지 않으면 0임을 알 수 있다.
또한, $n_i$는 class $i$에 속하는 모든 이미지 샘플의 수라는 것도 알 수 있다.
아래 수식을 이해하려면 Cross Entropy 에 대한 이해가 필요하다.
레이블의 공존성을 고려한 가중치 재조정

다른 건 볼 필요 없고 위 식에서 $ \widehat{r}^k_i$를 rebalancing weight로 사용하는데, 곱해서 클래스별 loss를 조절한다는 것만 알면 된다. $\widehat{r}^k_i $ 는 아래와 같이 정의한다.
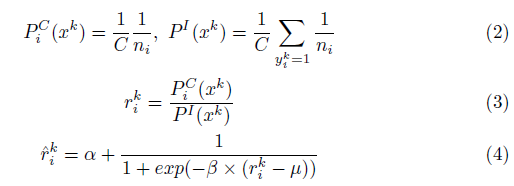
$P^C_i(x^k)$는 클래스(레이블)의 공존성을 고려하지 않고 여러 클래스 중 클래스$i$를 선택하고 선택한 클래스 $i$에서 해당 이미지를 선택할 확률(Class level sampling frequency)이고, $P^I(x^k)$는 $k$ 샘플이 가지는 모든 클래스 $i$에 대해 $P^C_i(x^k)$를 구하고 모두 더한 확률이다.(Instance-level sampling frequency)
(3)에서 알 수 있듯이 $r^k_i $ 는 Class level sampling frequency와 Instance-level sampling frequency의 비로 정해진다. 그런데 왜 하필 이런식으로 구하는지는 모르겠다. 그리고 $\widehat{r}^k_i $에는 전체적인 가중치 효과를 올리기 위해 $ \alpha $를 더한다. 또한, 적절한 범위의 값로 만들어 최적화 과정을 안정적으로 만들기 위해 ${r^k_i}$에 스무딩 함수를 적용한다. $\beta, \mu$는 하이퍼파라이미터로 함수의 모양을 바꿔 얼마나 빠르게 0에 가까워지고 1에 근접하는지를 조절할 수 있다.
부정 레이블의 과도한 억제(over-suppression)를 완화하기 위한 부정 허용 정규화(negative-tolerant regularization)
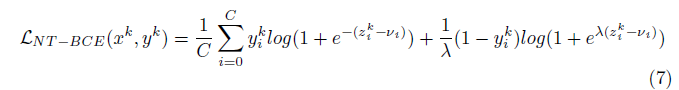
기존과 다른점은 negative 항에 부정 허용 정규화 $ \frac{1}{\lambda} $가 곱해졌고, $e^{z^k_i}$가 $\lambda e^{z^k_i -v_i}$가 된 것이다.
$\lambda$에 따라 얼마나 tolerant(허용) 할것인지에 대한 gradient를 조절 가능하며, ${z^k_i}$에 ${-v_i}$를 추가하여 class-specific bias에 얼마나 tolerant 할지를 조절이 가능하다.
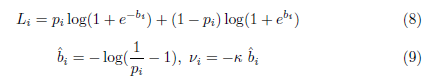
위 두가지 방법을 합쳐서 Distribution-balanced loss를 만들었다.

또한, 논문에서는 Loss에 적용되는 하이퍼파라미터에 대한 추가적인 연구가 필요하다고 말한다.
Pretrained 생성 모델 (Stable Diffusion)를 사용한 밸런싱
이 방법은 Diffusion 모델을 이용하여 Data Augmentation을 했더니 잘 된다는 논문을 보고 내가 떠올린 방법이다. 기존에 Data Augmentation을 하기 위해 생성 모델을 사용하는 방법이 널리 알려져 있었지만 pretrained 모델을 사용하여 클래스 밸런싱을 하는 내용은 없는 것 같다. 기존 밸런싱 기법들은 결국 기존 데이터만을 기반으로 보간하거나 가중치를 조절하는 방법을 사용할 수 밖에 없었기 때문에 기존 샘플의 Diversity가 낮으면 기존 샘플에서 크게 벗어나지 못하는 결과만을 생성한다. 하지만 이미지 데이터셋의 클래스 밸런싱에 10억장이 넘는 이미지를 학습한 StableDiffusion을 비롯한 이미지 생성 모델을 파인튜닝하여 사용하면 새로운 데이터를 더욱 다양하게 생성할 수 있으므로 더 넓은 범위의 학습이 가능할 것이라고 생각한다.
방법은 그냥 아무 기존 클래스 밸런싱 기법을 적용해서 학습시킨 뒤에, 해당 모델로 이미지를 생성하여 멀티 레이블 밸런싱을 해주면 끝이다. 반대로 단점도 존재하는데, 당연하게도 밸런싱을 위한 학습을 한번 더 해야 하기 때문에 컴퓨팅 비용이 증가한다는 점이다. 이 방법은 나 같이 필요한 클래스 데이터의 크기가 적거나 원하는 특정 클래스 데이터의 Diversity가 너무 적어 충분히 넒은 범위를 커버하지 못하는 경우에 사용할 만한 방법인 것 같다.
결론
이번에는 클래스 불균형 문제를 해결하는 여러 방법을 알아봤다. 어떤 상황에서 어떤 방법이 가장 적합한지는 본인이 판단해야 하겠지만 웬만하면 가중치를 조절하는 방식이 좋을 것 같다는 생각이 들었다. 물론, 위에서 제시한 여러 방법을 동시에 사용하는 것도 방법이다. 실제로 나는 특정 클래스의 데이터 양이 너무 적은 경우에는 Weight Balancing 방법과 단순 오버 샘플링 방법을 같이 사용한 적이 있다. 또한, 학습을 2단계로 나누어서 하는 방법도 존재한다. (A systematic study of the class imbalance problem in convolutional neural networks 이 논문에 다양한 클래스 불균형 문제 해결법에 대해 자세한 내용이 담겨 있으니 참고)
이번에 멀티 레이블 클래스 밸런싱에 대한 논문을 읽으면서 Distribution balanced loss를 Stable Diffusion에 적용해보는 실험을 해보면 재미있을 거 같다는 생각이 들었다. 언젠가 한번 직접 구현해보고 싶다.
소개한 방법 외에도 멀티 레이블 밸런싱에 더 좋은 방법을 아는 사람이 있다면 댓글로 알려주면 좋겠다.
참고 자료
https://haystar.tistory.com/m/81
https://techblog-history-younghunjo1.tistory.com/74
https://shinminyong.tistory.com/34
A systematic study of the class imbalance problem in convolutional neural networks
https://arxiv.org/abs/1710.05381
Effective Data Augmentation With Diffusion Models
https://arxiv.org/abs/2302.07944
Class-Balanced Loss Based on Effective Number of Samples
https://arxiv.org/abs/1901.05555
Distribution-Balanced Loss for Multi-Label Classification in Long-Tailed Datasets
'AI' 카테고리의 다른 글
| [딥러닝] Z-Image 이미지 생성 모델 원리, 테크니컬 리포트 분석 및 요약 (1) | 2025.11.30 |
|---|---|
| Stable Diffusion WebUI에서 프롬프트만으로 과적합된 모델을 살리는 팁(Prompt Editing) (0) | 2023.03.10 |
| [딥러닝]Stable Diffusion에서 너무 어두운 이미지를 학습하지 못하는 이유와 해결 방법(noise offset에 대하여) (0) | 2023.03.04 |
| [딥러닝 연구] Classifier-Free-Guidance(CFG)와 Stable diffusion 파인튜닝 (0) | 2023.02.18 |
| [딥러닝]Text to Image 모델 드림부스 학습의 Diversity를 높이는 방법 (4) | 2023.02.01 |